What is tag management?
Tag management, one of the darker arts of digital marketing, it tends to sit in the marketing camp but there is a strong case to educate your development team on its purpose, use and implementation.
A tag management solution (TMS) is a cloud based service designed to manage and deploy marketing tags – those little blocks of JavaScript required to enable marketing tools to interact with webpages – think Google Analytics, e.g.:
<script async src="https://www.googletagmanager.com/gtag/js?id=UA-202820265-2"></script>
<script>window.dataLayer = window.dataLayer || [];function gtag(){dataLayer.push(arguments);}gtag('js', new Date());gtag('config', 'UA-202820265-2');</script>
Example of a google Analytics JavaScript tag or snippet.
The Rise of the TMS
Enterprise Tag Management solutions have evolved into sophisticated tools offering features like Customer Data Platforms (CDPs) and Data Management Platforms (DMPs) but at the fundamental level, if you wish to better delineate and control the deployment and management of marketing analytics, then the ubiquitous Google Tag Manager (GTM) is your weapon of choice.
Free, with native support for Google’s other marketing tools, a large deployment footprint and notable experts in the analytics community; GTM is a defacto choice for most organisations getting into Tag Management.
I'm guessing, most of you 'pull'
However, the point of this article is to discuss some considerations that I would highlight based on my experience of utilising GTM across the more advanced deployments in the UK and Southeast Asia, predominantly in the user onboarding space where granular event measurement is a necessity.
Out of the box, Google Tag Manager is implemented client-side, meaning that an instance of it is created within the client’s browser memory space, when a user navigates to a website with GTM deployed.
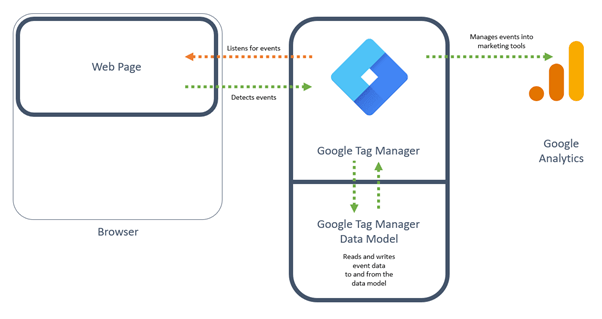 Figure 1 - Out of the box installation of GTM – the tag manager listens and event data is pulled.
Figure 1 - Out of the box installation of GTM – the tag manager listens and event data is pulled.
GTM uses the concept of triggers to ‘listen’ to events occurring as the user engages with the webpage, for example: a button click (CTA) and these in turn fire tags, the JavaScript blocks of code that marshal data to the marketing tools, such as Google Analytics.
The Google Tag Manager houses a Data Model that enables the collection of event details and associated parameters, and custom elements to be stored and interrogated when deciding which marketing tool to write data too and what data to write. This Data Model is an important concept for reasons I will dig into.
4 Problems with the 'Pull' method in Tag Management
The problem with the ‘pull’ approach is four-fold;
- A marketing led requirement to capture events and data points that may not have been considered during the build phase, due to a change in the organisation’s strategy.
- The tag analyst needs to appreciate not only the HTML elements of a page but also the user journey (events), a replication and duplication of effort that the developers have taken.
- Most webpages with optimised user experiences, especially for onboarding funnels Web2.0 concepts such as Single Page Applications, where pages do not reload as the user progresses – think of how Facebook updates as you post and comment.
- Any future code changes may prevent the tag manager from detecting existing or new events.
Looking at the out of the box installation of Google Tag Manager, in figure 2 below, we can see where the installation breaks down; due to events being hard to detect or another person requiring knowledge of the site HTML and expected user journeys.
The phrase ‘expected user journey’ also indicates assumptions you may be making about your customers and the data you will collect.
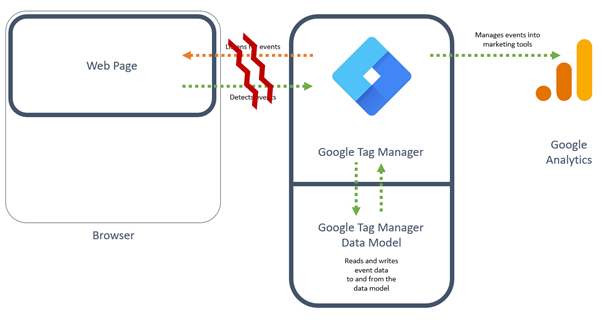 Figure 2 - Typical point of risk or weakness in a GTM implementation.
Figure 2 - Typical point of risk or weakness in a GTM implementation.
You should be 'pushing'!
My recommendation would be to make use of the capability within all modern web browsers to store information within memory using JavaScript arrays. When using Tag Managers and in this case Google Tag Manager, this array space is known as the dataLayer.
Implementing the dataLayer requires coordination between the tag analyst and the developer, ideally whilst the website is being built. I would recommend planning your analytics program very early on in a project’s lifecycle. Alternatively, conduct a specific exercise with these two individuals to revisit the site together.
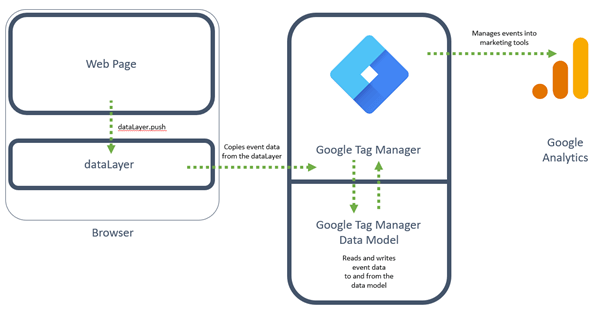 Figure 3 - the recommended GTM approach, using the 'push' method.
Figure 3 - the recommended GTM approach, using the 'push' method.
The diagram above, highlights the best approach, which is to write the event and any parameters to the dataLayer, when the user engages with the elements on the page.
Why 'pushing' to the Tag Manager works
Using the ‘push’ approach, rather than the ‘pull’ approach guarantees all events are written to the browsers memory within the dataLayer. As the tag manager is also running in the client-side memory space, it will duplicate the data within its own Data Model, leaving it easy to fire tags from triggers that are watching this controlled and formatted space and not the website.
Your projects and the websites will be more flexible and regression proof in terms of its analytics capability.
Some of you already practicing this approach will obviously highlight other issues, such as the client-side dependency on JavaScript, which can be prone to malfunction due to adblockers and the privacy measures being introduced by modern devices and browsers.
Server-side implementation of tag management to the rescue, but that is a blog post for another day and an approach that comes with other considerations such as operating costs, and lack of maturity in the market.
Post reviewed November 2024




SUBMIT YOUR COMMENT